I just finished working on LEARNINGlover.com: Hidden Marokv Models: The Backwards Algorithm. Here is an introduction to the script.
Suppose you are at a table at a casino and notice that things don’t look quite right. Either the casino is extremely lucky, or things should have averaged out more than they have. You view this as a pattern recognition problem and would like to understand the number of ‘loaded’ dice that the casino is using and how these dice are loaded. To accomplish this you set up a number of Hidden Markov Models, where the number of loaded die are the latent variables, and would like to determine which of these, if any is more likely to be using.
First lets go over a few things.
We will call each roll of the dice an observation. The observations will be stored in variables o1, o2, …, oT, where T is the number of total observations.
To generate a hidden Markov Model 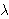 (HMM) we need to determine 5 parameters:
(HMM) we need to determine 5 parameters:
- The N states of the model, defined by S = {S1, …, SN}
- The M possible output symbols, defined by
 = {
= {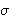 1, 2, …,M}
1, 2, …,M}
- The State transition probability distribution A = {aij}, where aij is the probability that the state at time t+1 is Sj, given that the state at time t is Si.
- The Observation symbol probability distribution B = {bj(k)} where bj(k) is the probability that the symbol k is emitted in state Sj.
- The initial state distribution
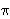 = {i}, where i is the probability that the model is in state Si at time t = 0.
= {i}, where i is the probability that the model is in state Si at time t = 0.
The HMMs we’ve generated are based on two questions. For each question, you have provided 3 different answers which leads to 9 possible HMMs. Each of these models has its corresponding state transition and emission distributions.
- How often does the casino change dice?
- 0) Dealer Repeatedly Uses Same Dice
- 1) Dealer Uniformly Changes Die
- 2) Dealer Rarely Uses Same Dice
- Which sides on the loaded dice are more likely?
- 0) Larger Numbers Are More Likely
- 1) All Numbers Are Randomly Likely
- 2) Smaller Numbers Are More Likely
| How often does the casino change dice? | ||||||||||
| Which sides on the loaded dice are more likely? |
|
One of the interesting problems associated with Hidden Markov Models is called the Evaluation Problem, which asks the question “What is the probability that the given sequence of observations O = o1, o2, …, oT are generated by the HMM . In general, this calculation, p{O | 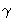 }, can be calculated by simple probability. However because of the complexity of that calculation, there are more efficient methods.
}, can be calculated by simple probability. However because of the complexity of that calculation, there are more efficient methods.
The backwards algorithm is one such method (as is the forward algorithm). It creates an auxiliary variable  t(i) which is the probability that the model has generated the partially observed sequence ot+1, …, oT, where 1
t(i) which is the probability that the model has generated the partially observed sequence ot+1, …, oT, where 1 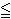 t T. This variable can be calculated by the following formula:
t T. This variable can be calculated by the following formula:
t(i) = j = 1 to N(t+1(j) * aij * bj(ot+1))
We also need that T(i) = 1, for 1 i N.
Once we have calculated the t(j) variables, we can solve the evaluation problem by p{O | } i = 1 to N1(i)
There is more on this example at LEARNINGlover.com: Hidden Marokv Models: The Backwards Algorithm.
Some further reading on Hidden Markov Models:
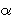 t(i) which is the probability that the model
t(i) which is the probability that the model 

 )2. We can get the average deviation from the mean then by computing the average of these values.
)2. We can get the average deviation from the mean then by computing the average of these values.  i = 1 to n((vi –
i = 1 to n((vi – 

 u, v
u, v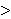 /
/ 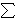 j = 1 to i-1 projuj(vi).
j = 1 to i-1 projuj(vi). 

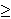 1
1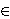 U,
U, 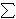 i | e
i | e 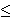 i
i 
