I was recently reading another math blog on Latin Squares and it brought the concept back to the forefront of my mind. For years I have wanted to do something with Latin Squares, but nothing generated enough of my interest to follow through on a project to completion. I had done some things to create a random Latin Square, but didn’t think that in itself was worthy of publication. So I let it linger.
Then I read this post. It talks about Latin Squares with added chess-based restrictions. So the one based on a chess knight’s move would say that in addition to being a Latin Square, there would be a restriction that cells (x, y) and (x +/- 2, y +/- 1) and (x +/- 1, y +/- 2) all be different. Likewise there is a bishop based restriction saying that cells (x, y) and (x +/- i, y +/- i) all be different. Because Latin Squares already assume that cells have horizontally and vertically different characters, this is the same as a queen’s move would be. Latin Squares also already take into account the rook moves. The remaining pieces talked about were the king based Latin squares. These say that for a cell (x, y) the cells (x+/-1, y+/-1) must all be different. There is an accompanying paper that I also found interesting.
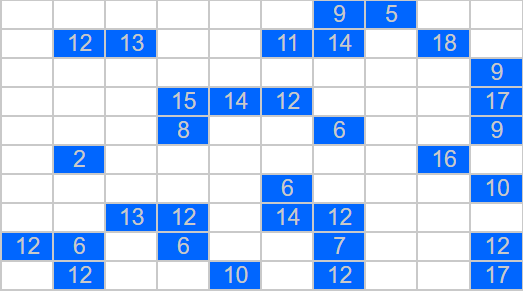
I read this blog article on the heels of having just improved my puzzle generations, so naturally I thought these would be good puzzles to attempt to generate and add to my puzzle section. So the first thing I did was complete a standard puzzle for Basic Latin Squares. These are under the standard assumptions saying that no number can appear more than once in any row or column. Then I used the max-submatrix problem to remove cells from this completed solution to create a puzzle. I played with this for a while and that was that. I attempted to add variants of the Latin Squares based on the chess pieces mentioned above, but with the exception of the trivial ones these were difficult and timely to generate. So again, that was that.
Until it wasn’t. I played around with the puzzles for a few hours (puzzles are addictive and started asking more questions. One of the first ones was simply how many clues do I need to have for a Latin Square to remain unique? I’m sure this problem has been studied, as it is a well studied problem for Sudoku puzzles, which are Latin Squares with an added restriction on the 3 by 3 subgrids. I found that the critical set of a Latin Square is the minimum number of cells from which a Latin Square can be reconstructed. Interesting.



Then I started thinking about visualizing Latin Squares. Obviously there is a way of visualizing them as a grid, possibly with colors instead of numbers or letters. That can make it more visually appealing. I was thinking about more of a graph theoretic approach though. So the first thing I did was something similar to the permutation graphs. With permutations, we had two lines, one representing the given permutation and one representing the lexicographically sorted permutation. Then lines are drawn between elements with the same value on different row. From this graph, we can construct a second graph consisting of the crossings (intersections of lines) in the first graph.

I used a similar approach to construct visualizations of Latin Squares. The first visualization is a node representing each cell in the square. Then lines are drawn between cells/nodes that have the same value. Once again, from this initial graph, we can look at the crossings and build a second graph, where we have the same node set, and an edge is present between two nodes if the two corresponding lines cross one another.

Apart from the (beautiful) visualization, the question I was asking myself is what information can be gained from these representations of Latin Squares. Could we gain anything from these crossing numbers? Would this last graphical representation always produce the original Latin Square? Or how similar must two Latin Squares be to get the same graph? Is there a graphical representation that preserves Latin Squares with less information?