
I have just finished a script that helps users understand mathematics through set theory and relations.
Much of our world deals with relationships – both in the sense of romantic ones or ones that show some interesting property between two sets. When mathematicians think of set theory, a relation between the set A and the set B is a set of ordered pairs, where the first element of the ordered pair is from the set A and the second element of the ordered pair id from the set B. So if we say that R is a relation on the sets A and B, that would mean that R consists of elements that look like (a, b) where a is in A and b is in B. Another way of writing this is that R is a subset of A x B. For more on subsets and cross product, I refer you to my earlier script work on set operations.
Relations can provide a useful means of relating an abstract concept to a real world one. I think of things like the QB rating system in the NFL as an example. We have a set of all quarterbacks in the NFL (or really all people who have thrown a pass) and we would like some means of saying that one QB is performing better than another. The set of statistics kept on a QB is a large set, so attempting to show that one QB is better by showing that every year that they played one is better in every statistical category can be (a) exhaustive, and (b) will lead to very few interesting comparisons. Most of the really good QBs have some areas that they are really good and others that they are not. The QB rating system provides a relation between the set of all QBs in the NFL and the set of real numbers. Once this relation was defined, we can say that one QB is performing better than another if his QB rating is higher. Similarly we can compare a QB to his own statistics at different points in his career to see the changes and trends.
This is just one example, and there are countless others that I could have used instead.
Once we understand what a relation is, we have several properties that we are interested in. Below I list four, although there are many more.
Properties of Relations:
A relation R is symmetric if whenever an element (a, b) belongs to R, then so does (b, a).
A relation R is reflexive if for every element a in the universe of the relation, the element (a, a) belongs to R.
A relation R is transitive if for every pair of elements (a, b) and (c, d) and b = c, then the element (a, d) belongs to R.
A relation R is anti-symmetric if the elements (a, b) and (b, a) do not belong to the relation whenever a is not equal to b.
Once we understand what a relation is, there are a few common ones that we are interested in. Below I list four, but again, I want to stress that these are some of the more common ones, but there are several others.
Types of Relations:
A relation R is a function (on its set of defined elements) if there do not exist elements (a, b) and (a, c) which both belong to R.
A relation R is an equivalence relation if R is symmetric, reflexive and transitive.
A relation R is a partial order set if R is anti-symmetric, reflexive and transitive.
A relation R is a total order set if it is a partial order set and for every pair of elements a and b, either (a, b) is in R or (b, a) is in R.
A partial order is just an ordering, but not everything can be compared to everything else. Think about the Olympics, and a sport like gymnastics. Consider the floor and the balance beam. One person can win gold on the floor and another person wins gold on the balance beam. That puts each of them in the “top” of the order for their particular section, but there’s no way of comparing the person who won the floor exercise to the person who won the balance beam. So we say the set is “partially ordered”. More formally, lets say that two people (person X and person Y) relate if they competed in the same event and the the first person (in this case person X) received an equal or higher medal in that event than the second person (in this case person Y). Obviously any person receives the same medal as themselves, so this relation is reflexive. And if Jamie received an equal or higher medal than Bobby and Bobby received an equal or higher medal than Chris, then Jamie must have received an equal or higher medal than Chris so this relation is transitive. To test this relation for anti-symmetry, suppose that Chuck received an equal or higher medal than Charlie and Charlie received an equal or higher medal than Chuck. This means that they must have received the same medal, but since only one medal is awarded at each color for each event (meaning one gold, one silver and one bronze…if this is not true, assume it is), this must mean that Chuck and Charlie are the same person, and this relation is thus anti-symmetric.
If we have a partial ordering where we can compare everything, then we say that the set is “totally ordered”.
An equivalence relation tries to mimic equality on our relation. So, staying with that example of the Olympics, an example of an equivalence relation could be to say that two athletes relate to one another if they both received the same color medal in their event (for the sake of argument lets assume that no athlete competes in more than one event). Then obviously an athlete receives the same medal as themselves, so this relation is reflexive. If two people received the same medal, then it doesn’t matter if we say Chris and Charlie or Charlie and Chris, so the relation is symmetric. And Finally if Chris received the same medal as Charlie an if Charlie received the same medal as Jesse, then all three people received the same medals, so Chris and Jesse received the same medals and this relation is transitive. Because this relation has these three properties, it is called an equivalence relation.





 {0, 1, 2, …, n} for some integer n, then the union of these sets forms a sample space. Lets call the sample space S. Suppose that we also have some set (also known as an event) A which is also a subset of S. Bayes’ Theorem considers the probability that one of these mutually exclusive events (one of the Bi‘s) caused the observed event (A).
{0, 1, 2, …, n} for some integer n, then the union of these sets forms a sample space. Lets call the sample space S. Suppose that we also have some set (also known as an event) A which is also a subset of S. Bayes’ Theorem considers the probability that one of these mutually exclusive events (one of the Bi‘s) caused the observed event (A).  Pr(Bi) Pr(A | Bi)
Pr(Bi) Pr(A | Bi)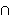 Bj. Likewise, the denominator the sum (over all the causal events) of the probaility of each causal event times the conditional probability of the observed event given that particular causal event. Each term in this denominator could be replaced b its equivalent staetment A
Bj. Likewise, the denominator the sum (over all the causal events) of the probaility of each causal event times the conditional probability of the observed event given that particular causal event. Each term in this denominator could be replaced b its equivalent staetment A 