I just finished a script on The Corral Puzzle.
I really enjoy puzzles. Even more than simply solving puzzles, I like understanding the thought process behind the puzzle process and trying to generate similar puzzles that are difficult in their own right yet still solvable. So far I’ve written works on The Sudoku Puzzle, The Nonogram Puzzle, and The Shade the Cells Puzzle. Today, I want to write about the Corral Puzzle.
The story behind how I discovered this puzzle is twofold. Initially, a coworker brought a Corral puzzle to my desk to see if I could solve it. It took me a minute, but I was able to get to the correct solution. We did a few more afterwards and I wrote some scripts to try to create new instances of these puzzles, but for a while it remained in the “unfinished work” category. Then sometime earlier this year, I purchased a book “Brain Workout: Math & Logic Puzzles” by Dave Tuller and Michael Rios. I was astonished to see that the first puzzle in this book was the Corral puzzle (which is where I was able to learn the name of the puzzles, as before they were just some things presented to me by a friend). The book has about 20 challenging puzzles (all of which I have not solved), but I was left again wondering how they came up with the puzzles. Before going further, I’ll give the rules of the puzzles and an example of a problem with the corresponding solution.
We are given a square grid (say 4 rows and 4 columns, or 5 rows and 5 columns, or in general n rows and n columns). Inside the grid some of the cells have a number inside of it. The object of the puzzle is for the user to draw a bag (also known as a corral) around the numbers inside the grid. The limitation is that the numbers tell how many neighboring cells can be “seen” from the given cell, looking only horizontally and vertically in both directions without reaching an endpoint of the bag. There are no restrictions on the shape of the bag except that it actually represents a closed loop inside the grid.
Consider the following example:

In this example, we are told the following hints:
- Cell (1, 2) (row 1, column 2) can see 6 of its neighbors.
- Cell (3, 1) can see 3 of its neighbors.
- Cell (4, 2) can see 5 of its neighbors.
- Cell (4, 3) can see 5 of its neighbors.
From these hints, we can reach the following solution:

Our corral in the solution would be to place the contiguous block of blue (turquoise) cells into a bag. We can check that the solution satisfies the assumptions as follows:
- Cell (1, 2) can see cells (1, 1), (1, 2), (1, 3), (2, 2), (3, 2), and (4, 2), which is 6 cells.
- Cell (3, 1) can see cells (3, 1), (3, 2), and (3, 3), which is 3 cells.
- Cell (4, 2) can see cells (1, 2), (2, 2), (3, 2), (4, 2), and (4, 3), which is 5 cells.
- Cell (4, 3) can see cells (1, 3), (2, 3), (3, 3), (4, 3), and (4, 2), which is 5 cells.
So we can see that this solution satisfies our assumptions.
Right now, I’m able to work with this by using it as an instance of The Set Cover Problem. The set that we would like to cover is the set of cells inside the Corral. The possible subsets are the cells in the corral that can be viewed by each cell inside the bag. Although Set Cover is an NP-Complete problem, we can still find feasible solutions using a number of algorithms. Here, I generate a feasible solution using the greedy approach.
There is still a problem with ambiguity. Sometimes the initial puzzle generated will allow for multiple Corrals to fit the original description. This is true with the example given as the following is also an optimal solution.

There is a thin line between revealing enough cells to ensure a unique solution and revealing too many cells such that the problem becomes trivial to solve. I’m still working on that and I may update the script in the future if I decide that the ambiguity is too much to live with.
So, enough talk. Go and check out my script on The Corral Puzzle and let me know what you think.






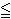 cki (notice that this is a more relaxed version of what we had when we were solving for the dual variables themselves).
cki (notice that this is a more relaxed version of what we had when we were solving for the dual variables themselves). 
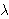 we need to determine 5 parameters:
we need to determine 5 parameters: = {
= {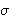 1,
1, 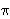 = {
= {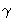 t(i) and
t(i) and 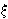 t(i, j). The variable
t(i, j). The variable 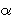 t(i) *
t(i) *  t(i) )
t(i) ) 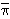 i =
i =  i,j =
i,j = 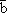 j(ok) =
j(ok) = 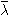 = {N,
= {N, 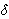 t(i) which has the highest probability that the partial observation sequence o1, …, ot can have, given that the current state is i. This variable can be calculated by the following formula:
t(i) which has the highest probability that the partial observation sequence o1, …, ot can have, given that the current state is i. This variable can be calculated by the following formula: